What Does Discovery Do?
The Network Discovery Tool automatically creates a detailed Inventory of Software and Hardware without using Agents. Updated and tested over 17 years of development, the field proven discovery engine, discovers large and small networks automatically.
Discovering the Network is fundamental to Mapping and Monitoring the Network as it learns what devices and links are present. That allows the Discovery to be used to automatically poll and monitor the network.
It also means setting up and displaying Netflow and all other features like Alerts know what IP addresses are associated with devices.
Important to note before running a Discovery:
- Platforms running Discoveries must have hibernation/standby disabled.
- Windows has an option to make Devices ‘Discoverable’, ensure this is enabled. Otherwise, devices will just be discovered as IP addresses – if at all.
Creating a Discovery – Step by Step
This section details how to create a Discovery in a step-by-step guide that includes images with yellow highlighter markup.
Creating a Database
- First and foremost, you must open the Toolbox software and log in.
- Next navigate to the Discover Network tab found at the top-left corner of the screen.
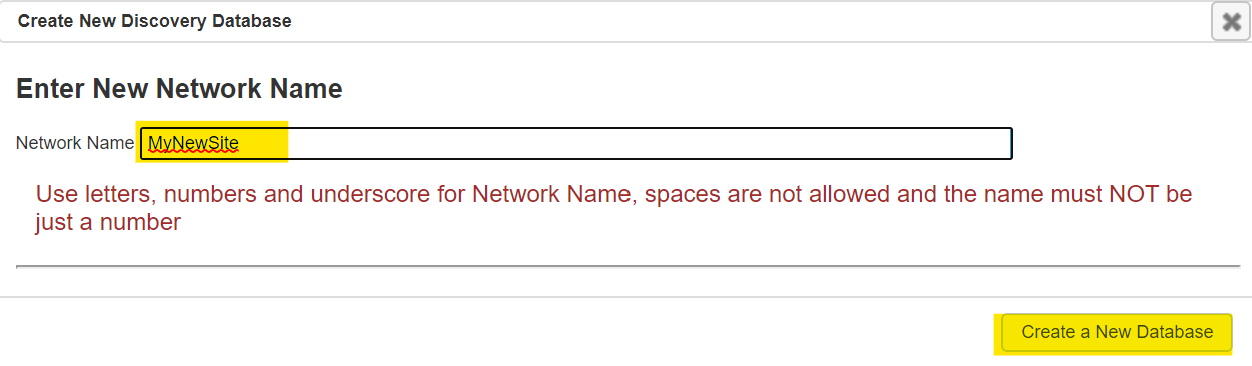
- Click on the button that says Create a New Discovery (Database)
- A window will appear asking you to name your Discovery, you may name it however you see fit as long as it follows the guidelines found on the window. Once an appropriate name has been entered click the button Create a New Database.
- A new window will appear notifying you that the process of creating the database has begun, press Ok and wait a few second for the database to be created.
- Once the database has been created it will be visible in the Discoveries Status and Control list at the bottom of the page. Any new discoveries will have a status indicating that it is New, see in the image below.




Configuring Discovery Settings
- Now click on the red text reading NO Settings>>> to configure the Discovery settings.
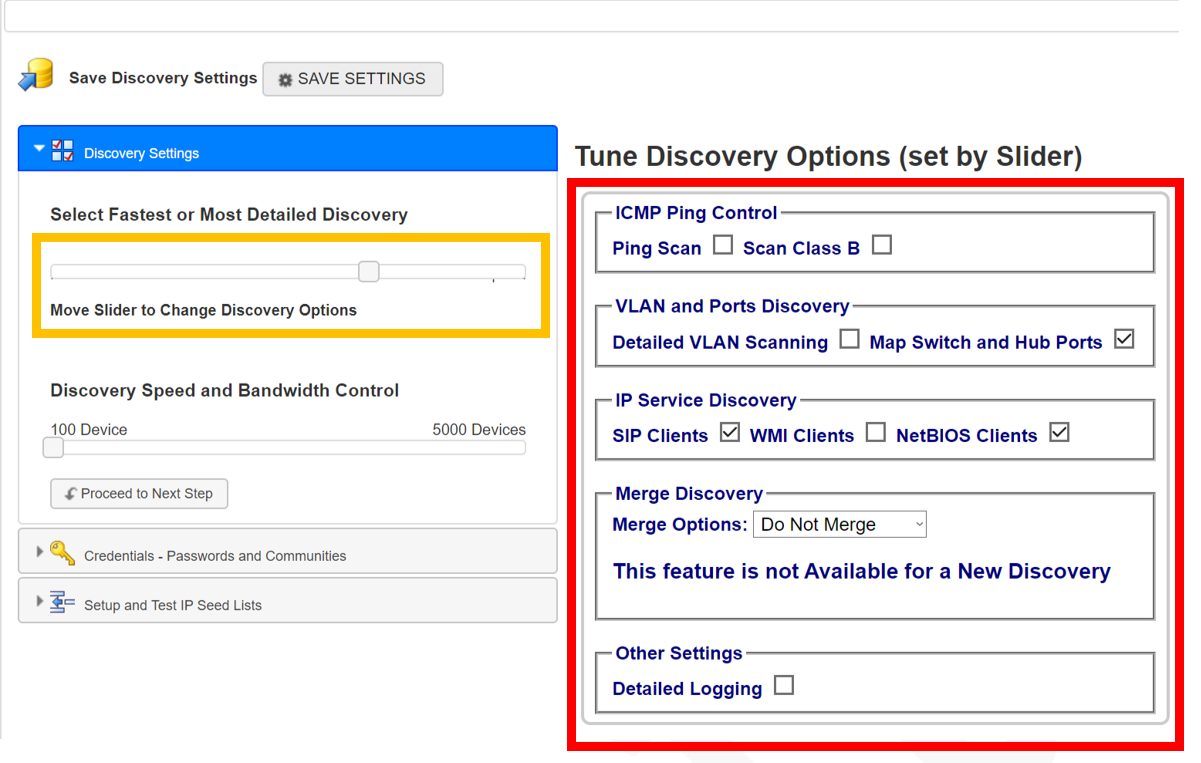
- A new window will appear where you may decide what you want the Discovery to scan the network for. There are two ways to decide what you want to scan for, the first is to manually tick all the boxes that you want to scan for (these are found on the right side, marked with the red square. Alternatively, you can use the slider on the left-hand side and the software will decide what to scan for based on how detailed of a scan you want to conduct (The slider is marked with the orange square, moving the slider to the left will make the scan more detailed and less detailed if it is moved to the right).
Note: The Merge Discovery feature can be useful if you are conducting several discoveries and don’t want to lose any information from previous discoveries.
Note: The Detailed Logging feature collects detailed Logging of the discovery which can be used by Toolbox Support to diagnose issues associated with the discovery - In the same step there is a slider titled Discovery Speed and Bandwidth Control, this slider will determine how many devices the software will scan simultaneously. If you are scanning a small network, you can leave the slider alone, but for larger networks you may choose to increase the slider to speed up the process (bear in mind this could put a strain on the PC/Server).
- Now click on the button beneath the sliders on the left-hand side that reads Proceed to Next Step.
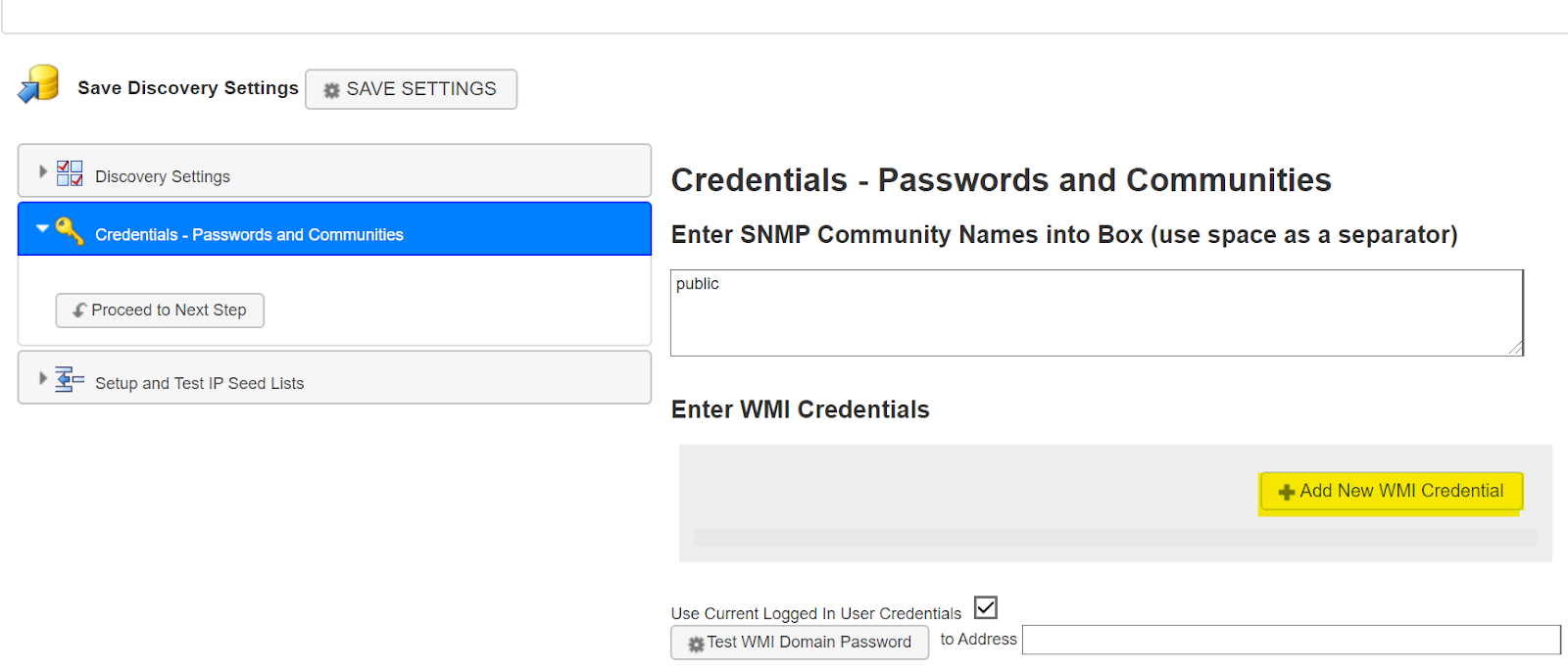
- In this section, the first step is to enter the networks SNMP Community Names into the text field. Most PCs will default to public so if you have a simple network this step can often be skipped, however in other networks you may need to add additional SNMP Community Names.
- Workstations do not usually have SNMP enabled. The key to getting the WMI to work is to make sure the machine the discovery is running on is allowed to ask the workstations for WMI information. Do this by entering WMI Credentials into the into the Discovery setup, please refer to your network administrator for help on this.
- You may also enter SNMPv3 Credentials by clicking on the “+” icon under the heading Enter SNMP Version 3 Credentials (Shown by the arrow in the image below)
- Click on the button Proceed to Next Step found on left-hand side.
- The following step is optional but is highly recommended as it decreases the Discovery length drastically.
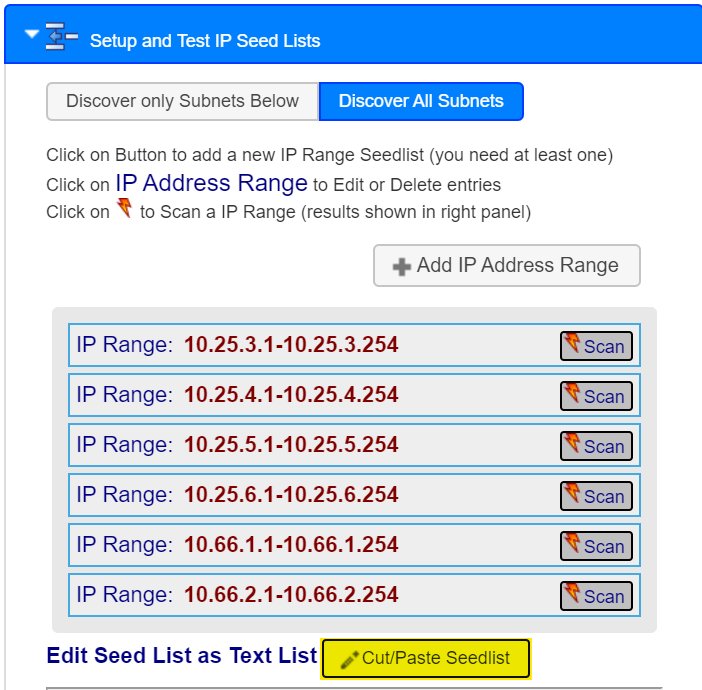
You can import a range of known IP addresses into the Discovery facility, effectively creating a list of seed addresses that then provide a means of speeding up the discovery process, as the Discovery Engine will bypass the early discovery stages and immediately activate SNMP operations for the listed addresses.
There are two ways to create a seed list and they work in conjunction with one another:- Manually Add ranges one at a time using the Add IP Address Range button, this method works well for a couple of ranges.
- The second method is to paste a saved text file seed list into the prompt that appears once the Cut/Paste Seedlist button is pressed, this method works great if you have many seed list ranges.
Note: You can check that the start parameters are ok, prior to starting the discovery. Do this by clicking on the Scan button to initiate a test to an IP Range, this can take several minutes.
- Manually Add ranges one at a time using the Add IP Address Range button, this method works well for a couple of ranges.
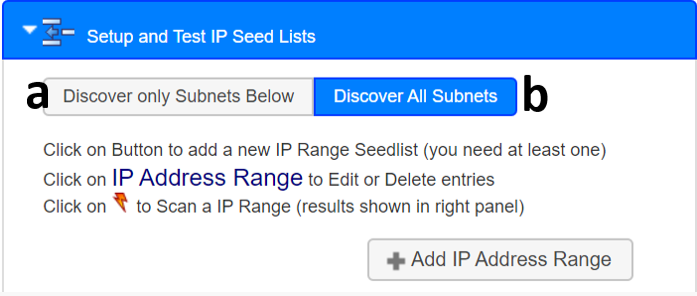
- There is an additional option under the Setup and Test IP Seed Lists tab, and these are to either Discover only Subnets Below, or to Discover all Subnets. An explanation of what these do, are as follows:
- Selecting Discover only Subnets Below option will ensure that once all the addresses in the Seed List are processed the discovery will stop, this method allows you to restrict your discovery to a defined range of addresses.
- Selecting Discover All Subnets option will ensure that all the addresses in the Seed List are processed first, then the system will continue to operate to find more devices.





- Make sure to SAVE SETTINGS, otherwise none of the changes you made will be saved. This button is found in the top left corner of the Discovery Settings window.

Running the Discovery
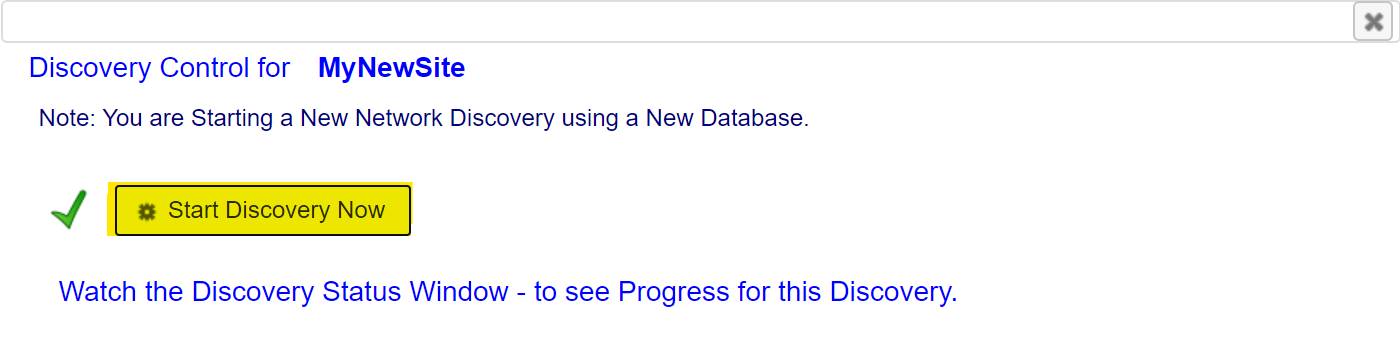
- To start the Discovery process, click on the start button, marked in the image below with yellow.
- A new window will appear click Start Discovery Now.
- Now you must wait for the Discovery to complete. You can monitor the progress of the Discovery in the Discovery Status Window. You may also at any time cancel the Discovery by clicking the Abort Discovery button at the top of the GUI, but keep in mind that this process can take a long time complete.
- Once the Discovery is completed you will be greeted with this message
- You now will also see that a Summary Report has been produced in the righthand panel of the GUI and will in essence look something like the image below. It contains counts of discovered devices organised by device category.
Only devices that respond to SNMP will be identified and classified. Unknown devices can be mailed to your reseller and included in a release.




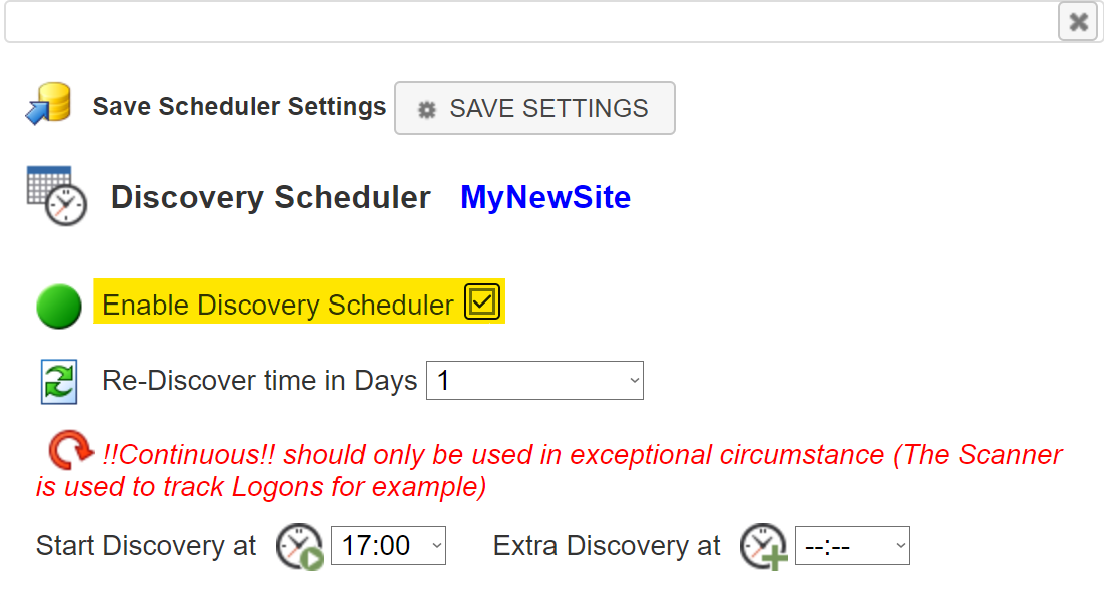
Discovery Scheduler
This feature has the capability to automatically schedule and execute Network Discoveries using the Toolbox’s web GUI. The following guide shows how to setup the Discovery Scheduler in a step-by-step manner.
- First you must have completed a Discovery in order to setup the Discovery Scheduler.
- Next find the column named Scheduler Controller in the Discovery grid, and click on the three arrows “>>>” under Set-up.
- A new window will appear, click on the tick box to enable the Discovery Scheduler. If at any point in the future you wish to disable this feature just uncheck this box and SAVE SETTINGS.
- Next decide how often you wish to run the Discovery. Note that the !!Continuous!! option starts a new discovery as soon as the Discovery Engine is free, this option is seldom recommended.
- Now you can decide at what time the discovery will start. You may also decide whether you want to run an Extra Discovery on the same day.
- Lastly click SAVE SETTINGS otherwise none of the changes will be saved.